publications
I joined the PhD program at ASU in 2023 with a research focus on compositonal robot learning. Prior to that, I researched document automation and text generation at Wells Fargo.
2026
-
 PokeNet: Learning Kinematic Models of Articulated Objects from Human ObservationsAnmol Gupta, Weiwei Gu, Omkar Patil, and 2 more authorsIEEE International Conference on Robotics and Automation (ICRA), 2026
PokeNet: Learning Kinematic Models of Articulated Objects from Human ObservationsAnmol Gupta, Weiwei Gu, Omkar Patil, and 2 more authorsIEEE International Conference on Robotics and Automation (ICRA), 2026Articulation modeling enables robots to learn how an object’s joints move so they can manipulate it effectively. PokeNet is an end-to-end framework that learns articulation models from a single human demonstration without prior object knowledge. From point cloud sequences, it predicts joint parameters, infers manipulation order, and tracks joint states over time.
@article{gupta2025learning, title = {PokeNet: Learning Kinematic Models of Articulated Objects from Human Observations}, author = {Gupta, Anmol and Gu, Weiwei and Patil, Omkar and Lee, Jun Ki and Gopalan, Nakul}, journal = {IEEE International Conference on Robotics and Automation (ICRA)}, year = {2026}, } -
 Factorizing Diffusion Policies for Observation Modality PrioritizationOmkar Patil, Prabin Rath, Kartikay Pangaonkar, and 2 more authorsIEEE International Conference on Robotics and Automation (ICRA), 2026
Factorizing Diffusion Policies for Observation Modality PrioritizationOmkar Patil, Prabin Rath, Kartikay Pangaonkar, and 2 more authorsIEEE International Conference on Robotics and Automation (ICRA), 2026Diffusion models have been extensively leveraged for learning robot skills from demonstrations. These policies are conditioned on several observational modalities such as proprioception, vision, and tactile. However, observational modalities have varying levels of influence for different tasks that diffusion policies fail to capture. In this work, we propose Factorized Diffusion Policies (FDP), a novel policy formulation that enables observational modalities to have differing influence on the action diffusion process by design. This results in learning policies where certain observation modalities can be prioritized over others, such as vision > tactile or proprioception > vision. FDP achieves modality prioritization by factorizing the observational conditioning for the diffusion process, resulting in more performant and robust policies. Our factored approach shows strong performance improvements in low-data regimes, with a 15% absolute improvement in success rate on several simulated benchmarks when compared to a standard diffusion policy that jointly conditions on all input modalities. Moreover, our benchmark and real-world experiments show that factored policies are naturally more robust, with a 40% higher absolute success rate across several visuomotor tasks under distribution shifts such as visual distractors or camera occlusions, where existing diffusion policies fail catastrophically. FDP thus offers a safer and more robust alternative to standard diffusion policies for real-world deployment. Videos are available at https://fdp-policy.github.io/fdp-policy/.
@article{patil2025factorizing, title = {Factorizing Diffusion Policies for Observation Modality Prioritization}, author = {Patil, Omkar and Rath, Prabin and Pangaonkar, Kartikay and Rosen, Eric and Gopalan, Nakul}, journal = {IEEE International Conference on Robotics and Automation (ICRA)}, year = {2026}, }
2024
-
 Learning Temporally Composable Task Segmentations with LanguageDivyanshu Raj, Omkar Patil, Weiwei Gu, and 2 more authorsIn 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Oct 2024
Learning Temporally Composable Task Segmentations with LanguageDivyanshu Raj, Omkar Patil, Weiwei Gu, and 2 more authorsIn 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Oct 2024In this work, we present an approach to identify sub-tasks within a demonstrated robot trajectory with the supervision provided by language instructions. Learning longer horizon tasks is challenging with techniques such as reinforcement learning and behavior cloning. Previous approaches have split these long tasks into shorter tasks that are easier to learn by using statistical change point detection methods. However, classical changepoint detection methods function only with low dimensional robot trajectory data and not with high dimensional inputs such as vision. Our goal in this work is to split longer horizon tasks, represented by trajectories into shorter horizon tasks that can be learned using conventional behavior cloning approaches using guidance from language. In our approach we use techniques from the video moment retrieval problem on robot trajectory data to demonstrate a high-dimensional generalizable change-point detection approach. Our proposed moment retrieval-based approach shows a more than 30% improvement in mean average precision (mAP) for identifying trajectory sub-tasks with language guidance compared to that without language. We perform ablations to understand the effects of domain randomization, sample complexity, views, and sim-to-real transfer of our method. In our data ablation we find that just with a 100 labelled trajectories we can achieve a 61.41 mAP, demonstrating the sample efficiency of using such an approach. Further, behavior cloning models trained on our segmented trajectories outperform a single model trained on the whole trajectory by up to 20%.
@inproceedings{10802712, author = {Raj, Divyanshu and Patil, Omkar and Gu, Weiwei and Baral, Chitta and Gopalan, Nakul}, booktitle = {2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, title = {Learning Temporally Composable Task Segmentations with Language}, year = {2024}, volume = {}, number = {}, pages = {5195-5202}, keywords = {Accuracy;High dimensional data;Pipelines;Cloning;Reinforcement learning;Trajectory;Complexity theory;Standards;Intelligent robots}, doi = {10.1109/IROS58592.2024.10802712}, issn = {2153-0866}, month = oct, } -
 Hardware-Software Co-Design for Path Planning by DronesAyushi Dube*, Omkar Patil*, Gian Singh, and 2 more authorsIn 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Oct 2024
Hardware-Software Co-Design for Path Planning by DronesAyushi Dube*, Omkar Patil*, Gian Singh, and 2 more authorsIn 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Oct 2024This work consists of two main components: designing a hardware-software co-design, MT+, for adapting the Mikami-Tabuchi algorithm for on-board path planning by drones in a 3D environment; and development of a specialized custom hardware accelerator CDU, as a part of MT+, for parallel collision detection. Collision detection is a performance bottleneck in path planning. MT+ reduces the delay in path planning without using any heuristic. A comparative analysis between the state-of-the-art path planning algorithm A* and Mikami-Tabuchi is performed to show that Mikami-Tabuchi is faster than A* in typical real-world environments. In custom-generated environments, path planning using Mikami-Tabuchi shows a latency improvement of 1.7× across varying average sizes of obstacles and 2.7× across varying obstacle density over state-of-the-art path planning algorithm, A*. Further, the experiments show that the co-design achieves speedups over a full software implementation on CPU, averaging between 10% to 60% across different densities and sizes of obstacles. CDU area and power overheads are negligible against a conventional single-core processor.
@inproceedings{10802753, author = {Dube, Ayushi and Patil, Omkar and Singh, Gian and Gopalan, Nakul and Vrudhula, Sarma}, booktitle = {2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, title = {Hardware-Software Co-Design for Path Planning by Drones}, year = {2024}, volume = {}, number = {}, pages = {8141-8146}, keywords = {Three-dimensional displays;Software algorithms;Parallel processing;Path planning;Software;Delays;Collision avoidance;Hardware acceleration;Intelligent robots;Drones}, doi = {10.1109/IROS58592.2024.10802753}, issn = {2153-0866}, month = oct, } -
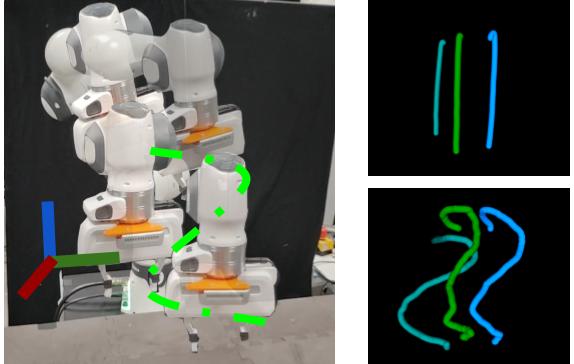 Composing Diffusion Policies for Few-shot Learning of Movement TrajectoriesOmkar Patil, Anant Sah, and Nakul GopalanarXiv preprint arXiv:2410.17479, Oct 2024
Composing Diffusion Policies for Few-shot Learning of Movement TrajectoriesOmkar Patil, Anant Sah, and Nakul GopalanarXiv preprint arXiv:2410.17479, Oct 2024Humans can perform various combinations of physical skills without having to relearn skills from scratch every single time. For example, we can swing a bat when walking without having to re-learn such a policy from scratch by composing the individual skills of walking and bat swinging. Enabling robots to combine or compose skills is essential so they can learn novel skills and tasks faster with fewer real world samples. To this end, we propose a novel compositional approach called DSE- Diffusion Score Equilibrium that enables few-shot learning for novel skills by utilizing a combination of base policy priors. Our method is based on probabilistically composing diffusion policies to better model the few-shot demonstration data-distribution than any individual policy. Our goal here is to learn robot motions few-shot and not necessarily goal oriented trajectories. Unfortunately we lack a general purpose metric to evaluate the error between a skill or motion and the provided demonstrations. Hence, we propose a probabilistic measure - Maximum Mean Discrepancy on the Forward Kinematics Kernel (MMD-FK), that is task and action space agnostic. By using our few-shot learning approach DSE, we show that we are able to achieve a reduction of over 30% in MMD-FK across skills and number of demonstrations. Moreover, we show the utility of our approach through real world experiments by teaching novel trajectories to a robot in 5 demonstrations.
@article{patil2024composingdiffusionpoliciesfewshot, title = {Composing Diffusion Policies for Few-shot Learning of Movement Trajectories}, author = {Patil, Omkar and Sah, Anant and Gopalan, Nakul}, journal = {arXiv preprint arXiv:2410.17479}, year = {2024}, eprint = {2410.17479}, archiveprefix = {arXiv}, primaryclass = {cs.RO}, url = {https://arxiv.org/abs/2410.17479}, }
2022
-
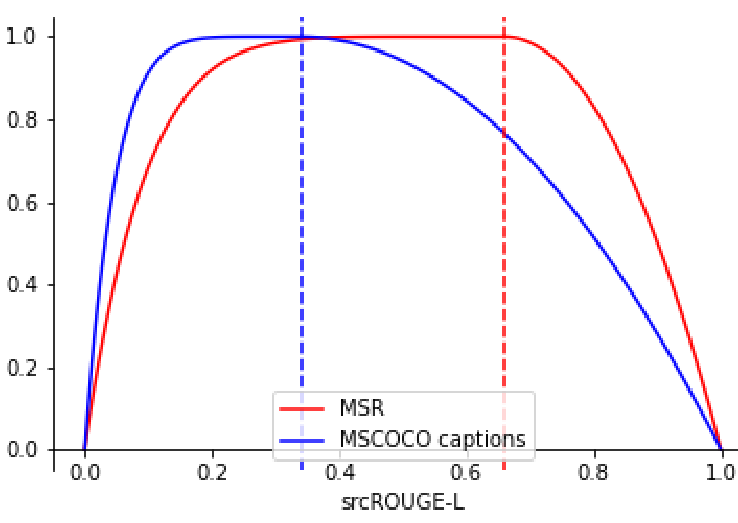 Understanding metrics for paraphrasingOmkar Patil, Rahul Singh, and Tarun JoshiarXiv preprint arXiv:2205.13119, Oct 2022
Understanding metrics for paraphrasingOmkar Patil, Rahul Singh, and Tarun JoshiarXiv preprint arXiv:2205.13119, Oct 2022Paraphrase generation is a difficult problem. This is not only because of the limitations in text generation capabilities but also due that to the lack of a proper definition of what qualifies as a paraphrase and corresponding metrics to measure how good it is. Metrics for evaluation of paraphrasing quality is an on going research problem. Most of the existing metrics in use having been borrowed from other tasks do not capture the complete essence of a good paraphrase, and often fail at borderline-cases. In this work, we propose a novel metric ROUGEP to measure the quality of paraphrases along the dimensions of adequacy, novelty and fluency. We also provide empirical evidence to show that the current natural language generation metrics are insufficient to measure these desired properties of a good paraphrase. We look at paraphrase model fine-tuning and generation from the lens of metrics to gain a deeper understanding of what it takes to generate and evaluate a good paraphrase.
@article{patil2022understanding, title = {Understanding metrics for paraphrasing}, author = {Patil, Omkar and Singh, Rahul and Joshi, Tarun}, journal = {arXiv preprint arXiv:2205.13119}, year = {2022}, url = {https://arxiv.org/abs/2205.13119}, }
2021
-
 Document automation architectures and technologies: A surveyMohammad Ahmadi Achachlouei, Omkar Patil, Tarun Joshi, and 1 more authorarXiv preprint arXiv:2109.11603, Oct 2021
Document automation architectures and technologies: A surveyMohammad Ahmadi Achachlouei, Omkar Patil, Tarun Joshi, and 1 more authorarXiv preprint arXiv:2109.11603, Oct 2021This paper surveys the current state of the art in document automation (DA). The objective of DA is to reduce the manual effort during the generation of documents by automatically integrating input from different sources and assembling documents conforming to defined templates. There have been reviews of commercial solutions of DA, particularly in the legal domain, but to date there has been no comprehensive review of the academic research on DA architectures and technologies. The current survey of DA reviews the academic literature and provides a clearer definition and characterization of DA and its features, identifies state-of-the-art DA architectures and technologies in academic research, and provides ideas that can lead to new research opportunities within the DA field in light of recent advances in artificial intelligence and deep neural networks.
@article{achachlouei2021document, title = {Document automation architectures and technologies: A survey}, author = {Achachlouei, Mohammad Ahmadi and Patil, Omkar and Joshi, Tarun and Nair, Vijayan N}, journal = {arXiv preprint arXiv:2109.11603}, year = {2021}, url = {https://arxiv.org/abs/2109.11603}, } -
 Visual Localization Using Capsule NetworksOmkar PatilIn International Conference on Computer Vision and Image Processing, Oct 2021
Visual Localization Using Capsule NetworksOmkar PatilIn International Conference on Computer Vision and Image Processing, Oct 2021Visual localization is the task of camera pose estimation, and is crucial for many technologies which involve localization such as mobile robots and augmented reality. Several convolutional neural network models have been proposed for the task against the more accurate geometry based computer vision techniques. However, they have several shortcomings and to our knowledge, this was the first effort that explored the use of an alternative architecture based on capsule-networks for the task. We achieved better results with capsules than with baseline-CNN PoseNet on small NORB dataset, modified for the task of camera pose estimation. Feature visualizations for both the networks produced more insights on their performance and behaviour. We found that there is a scope for improvement and hence propose few directions for future efforts.
@inproceedings{patil2021visual, title = {Visual Localization Using Capsule Networks}, author = {Patil, Omkar}, booktitle = {International Conference on Computer Vision and Image Processing}, pages = {164--174}, year = {2021}, organization = {Springer}, url = {https://link.springer.com/chapter/10.1007/978-3-031-11346-8_15}, }